Beyond Plain Text: Egnyte's Journey to Structured Data Extraction in RAG Systems
When we first launched Egnyte’s AI features built on retrieval-augmented generation (RAG), customer response was overwhelmingly positive. Users could quickly find and synthesize information from vast document repositories with accuracy and context.
But success breeds ambition. As customers grew comfortable with the system, they began exploring new use cases that revealed a limitation: while our RAG excelled with plain text, it struggled with tables, charts, and other structured formats.
This limitation wasn't surprising. Traditional RAG approaches process natural language effectively but lack the capability to handle the spatial and relational nature of tabular data, where information is encoded through position, hierarchy, and visual organization.
We saw this challenge as an opportunity for innovation. By extending our RAG pipeline to handle structured data extraction, we could unlock new value for customers while advancing RAG technology.
This post details our journey into structured extraction—our approach, technical solutions, and performance improvements. Whether you're facing similar challenges or are interested in RAG systems and structured data, we hope our experiences provide valuable insights.
Problem Statement: The Structured Data Challenge
The limitations we encountered with structured formats represented a significant challenge, as they comprise a substantial portion of our customer files.
We faced quite a few technical challenges, including:
- Positional understanding: In tables, a cell's meaning depends on its position relative to headers, creating spatial relationships that text-based RAG couldn't interpret.
- Relational complexity: Converting multi-dimensional tables into text strings resulted in the loss of information about data relationships.
- Implicit calculations: Queries about tabular data often require aggregations or comparisons not explicitly stated in the document.
- Format variability: Tables appear in various layouts—simple grids, nested structures, merged cells, and image-embedded tables—making standardized extraction challenging.
- Mixed content: Documents typically contain combinations of tables and text, requiring content-type detection.
- Scale requirements: Our implementation needed to maintain performance across large volumes of customer data, requiring efficient processing pipelines.
- Cost efficiency: Enhanced extraction capabilities needed to be implemented without significantly increasing processing costs.
Our goal was to develop a solution that could identify and extract structured data, preserve relational information, enable computational reasoning, integrate with our existing pipeline, and scale effectively across diverse use cases.
Exploration Phase: Understanding Document Structure Patterns
Before implementing our solution, we conducted thorough research on the approaches to structured data processing. This phase brought to light the two key challenges:
Document Chunking Limitations
Our RAG pipeline divided documents into fixed-size chunks (2000 characters) for indexing and retrieval. While effective for plain text, this approach created problems for tabular data:
- Tables frequently exceeded chunk size limits.
- Tables split across chunks lost row/column relationships.
- Headers separated from data cells lost context.
- Complex tables with merged or nested cells became fragmented.
We considered increasing chunk sizes globally, but this introduced trade-offs:
- Reduced retrieval precision for plain text
- Increased processing and embedding costs
- Higher retrieval latency
- Expanded storage requirements
Table Representation Format
We needed an efficient way to represent tables that preserved structure while enabling accurate reasoning. We evaluated several formats, each with its own sets of pros and cons:
- HTML: Good structure preservation but high token usage
- Markdown: Balanced structure and token efficiency
- Tab/comma-separated: Compact but lost hierarchical relationships
- JSON/structured formats: Maintained relationships but increased token usage
The exploration phase made one thing abundantly clear—we needed to fundamentally rethink both how we chunked tables and how we represented them to the LLM while maintaining performance at scale.
Solution Overview
After identifying the chunk size limitations and table representation format challenges, we needed to determine the most effective extraction approach for structured data across diverse document types.
Comprehensive Tool Evaluation
We conducted an extensive evaluation of leading document processing and table extraction libraries across diverse test cases.
Tools and Libraries Evaluated
- Unstructured: A popular open-source document parsing toolkit
- PyMuPDF4LLM: A specialized PDF extraction library optimized for LLM pipelines
- Apryse (formerly PDFTron): A commercial document processing SDK
- Pandoc: A universal document converter
Extraction Test Cases
- Image PDF with tables with clear boundaries
- Excel sheets with complex tables
- Digital-first PDFs with tables
- Image PDFs with tables without visible boundaries
- Image PDFs with tables on dark backgrounds
- Image PDFs with handwritten bills of materials (BOMs)
- Digital-first PDFs with tables without visible boundaries
- Numerous other edge cases representing real-world customer documents
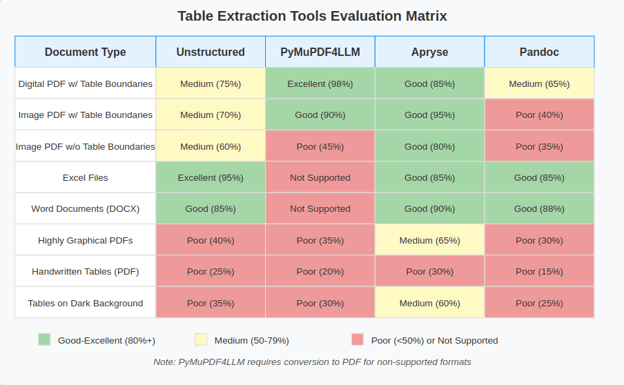
Our evaluation revealed a critical insight: no single extraction tool excelled across all document types and formats. Each had distinct strengths and weaknesses depending on specific document characteristics, leading us to develop a targeted multi-strategy approach.
Solving the Table Representation Format Challenge
After evaluating various representation formats for extracted tables, we conducted systematic testing across HTML, Markdown, JSON, and CSV formats. Our evaluation focused on three key metrics:
- Token efficiency: Measuring how compactly each format represented complex tables
- Structural fidelity: Assessing how well each format preserved relationships between cells
- LLM reasoning performance: Testing how effectively language models could interpret and reason with each format
Our benchmarking revealed Markdown as the optimal solution, offering:
- 40% reduction in token usage compared to HTML while maintaining structural integrity
- Better preservation of hierarchical relationships than CSV
- Improved LLM reasoning performance compared to alternative formats
- Consistent representation regardless of source format
This standardization on Markdown provided the foundation for addressing our document chunking limitations.
Solving Document Chunking Limitations: The Decoupling Approach
To resolve document chunking limitations, we implemented a four-step decoupling strategy that separates table storage from text chunking and indexing:
- Separate table storage: Complete tables are stored in Markdown format as separate extraction artifacts, each with a unique identifier.
- Reference system: During text processing, our extraction system identifies table-related text and tags it with the corresponding table identifier.
- Enhanced indexing: We added two critical fields to our hybrid search index:
- A table identifier field linking text chunks to source tables
- A "Type" field classifying content as title, paragraph, text, image, table, table caption, etc.
- Intelligent retrieval processing - When chunks are retrieved, our hybrid search service:
- Identifies table references requiring specialized handling
- Retrieves the complete table using the table identifier
- Provides the full table context to the LLM in the optimized markdown format
Document Layout Extraction: A Technical Breakdown
Integration With Existing Infrastructure and Processing Pipelines
Curious about how extraction and RAG work together? Take a look at Part 1: 'How Egnyte Built its Turnkey Retrieval Augmented Generation Solution' for a deep dive.
Here's how the new layout extraction component integrates with our existing infrastructure.
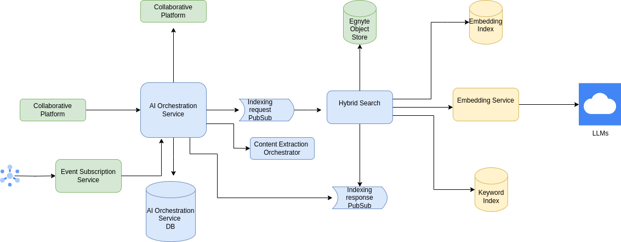
Zooming in on Content Extraction Orchestrator
Our Layout Extraction solution was designed to integrate seamlessly with our established content extraction ecosystem. This diagram illustrates how the Layout Extractor components fit within our broader architecture:
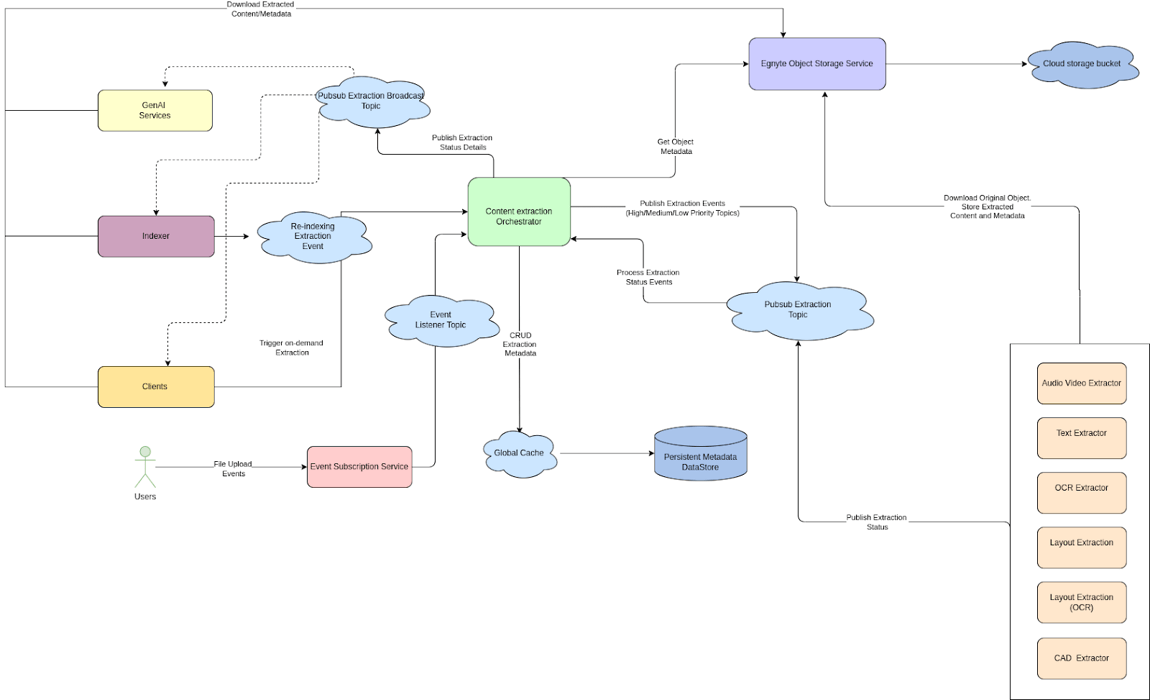
Content Extraction Orchestration Framework Integration
The Content Extraction Orchestrator Service is the central orchestration hub for our document extraction pipeline. Our implementation leverages several key components of this existing infrastructure.
AI Orchestration Service Components Integration
Providing the critical link between storage and retrieval is the AI Orchestration Service, which:
- Receives search results containing both text and structural references
- Detects table reference markers in retrieved chunks
- Pulls complete table Markdown from Egnyte Object Store when references are encountered
- Reconstructs the full context by replacing references with complete structural content
- Provides this enriched context to the LLM Interface Service
This dynamic reconstruction approach is particularly important, as it ensures that:
- LLMs receive complete structural context (entire tables)
- Search precision isn't compromised by oversized chunks
- Storage remains efficient without duplicating table content
- Document structure is preserved for proper reasoning
By leveraging our existing infrastructure components and enhancing them with layout-aware capabilities, we created a solution that efficiently processes structured documents while maintaining the performance and scaling characteristics of our established systems.
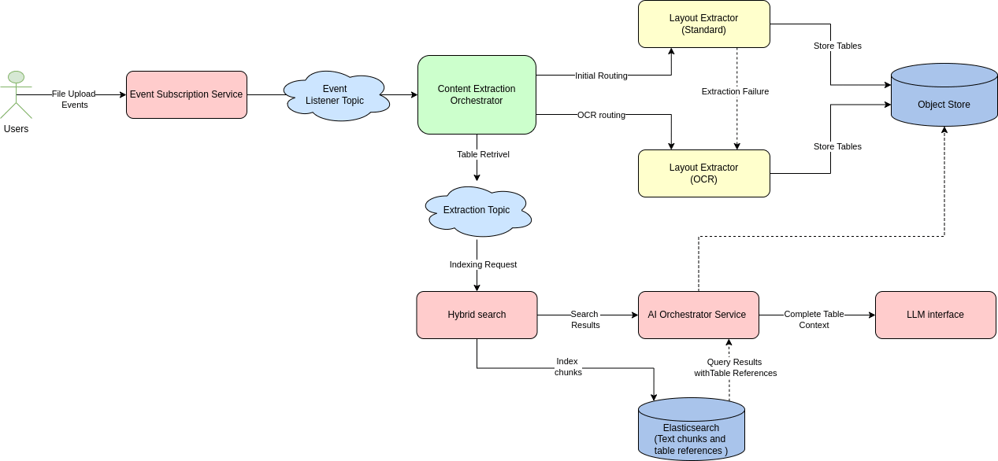
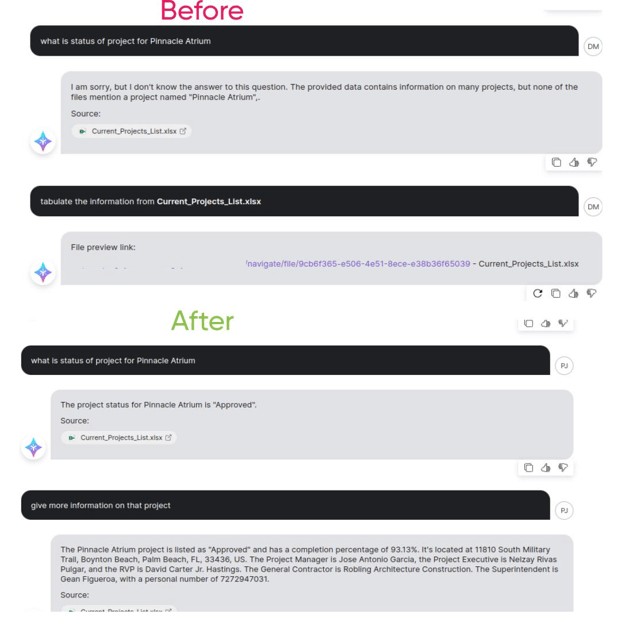
Table Processing Improvements: Enhanced Document Understanding
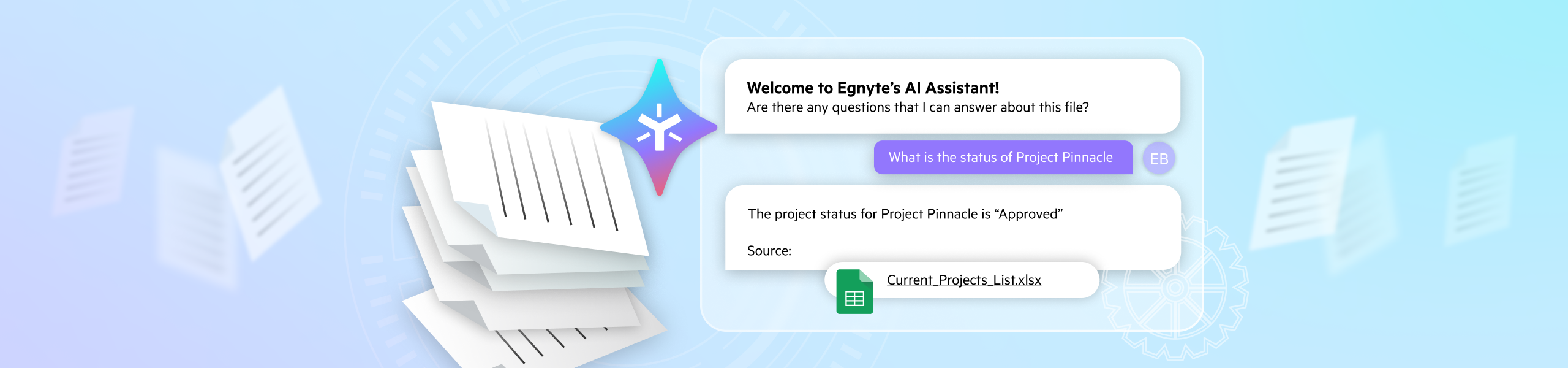
With this new approach we saw significant improvements in our ability to answer questions based on tabular data.
Our updated Layout Extraction engine showed significant improvements across multiple document types:
Table Processing:
- Before: Limited extraction of tabular data
- After: Accurate extraction with structural preservation
- Technical improvements:
- Row-level data retrieval capability
- Support for complex table structures
- Query processing against tabular data
Document Context Handling:
- Before: Inconsistent identification of document metadata
- After: More complete information extraction
- Project status identification
- Metadata retrieval
- Cross-referencing between document sections
Examples
Implementation results in specific cases:
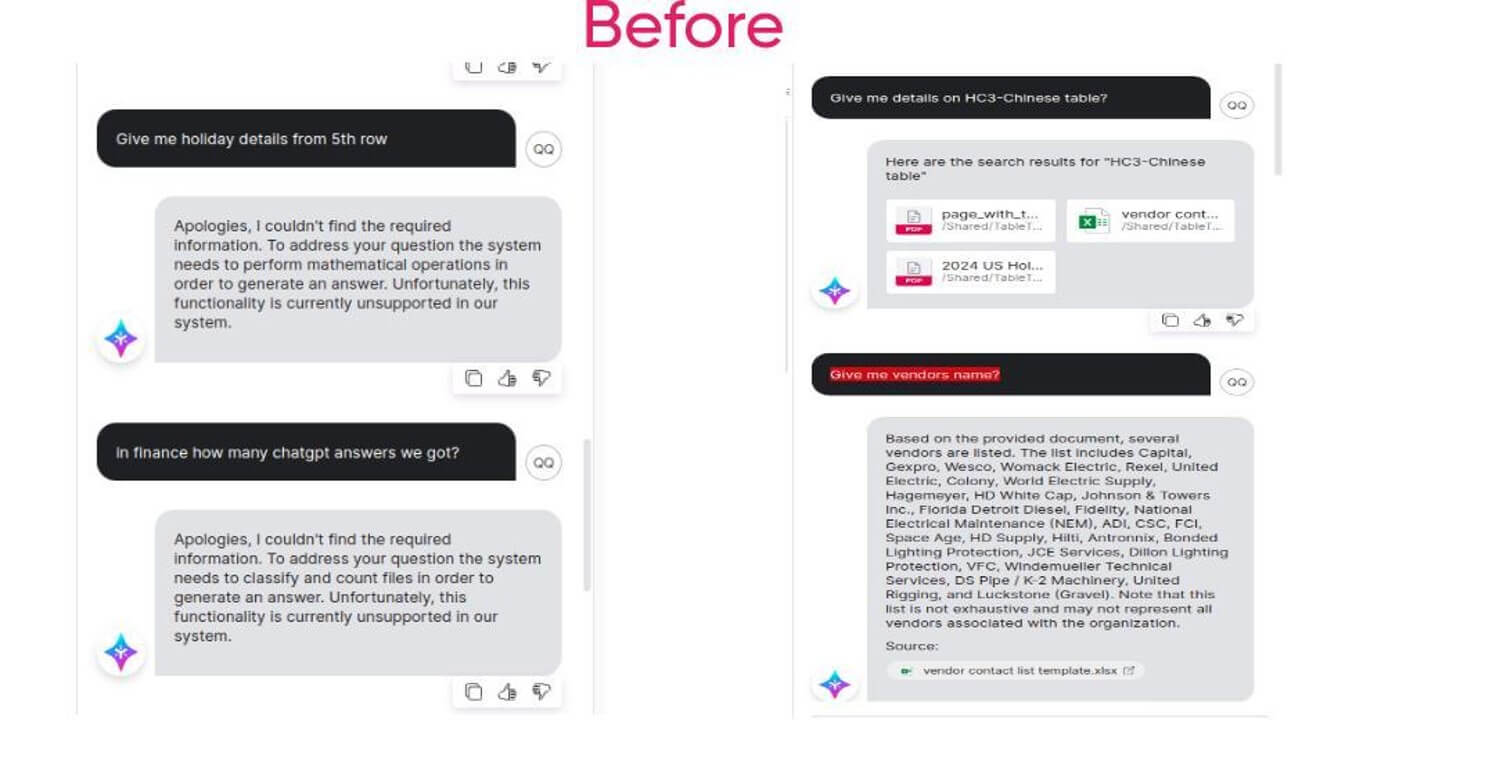
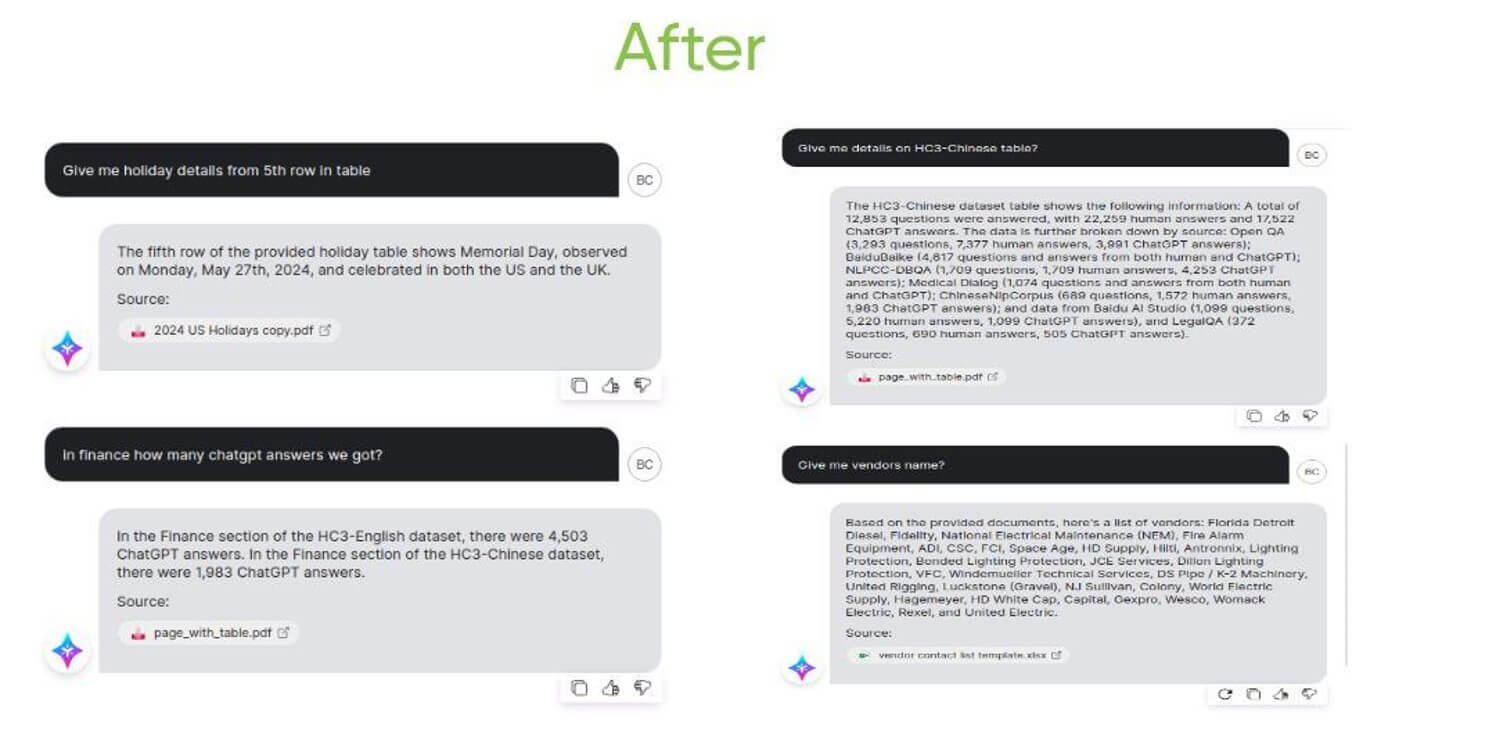
Employee holiday data:
- Initial limitation: Unable to extract row-specific information
- Improvement: Reliable extraction of specific rows from holiday tables
Project documentation:
- Previous limitation: Information retrieval failures
- Technical solution:
- Project status detection
- Metadata extraction
- Contextual information linking
Measurable Results
The technical improvements delivered several quantifiable benefits:
- Better structural preservation in complex documents
- Improved table interpretation capabilities
- Reduced information retrieval failures
- More accurate query responses for structured data
Our Layout Extraction engine now provides more reliable processing for documents containing mixed plain text and tabular content.
Future Development: Next Steps in Document Extraction
Building on our current text extraction capabilities, we're expanding into visual content processing to create a comprehensive document understanding system.
Image Content Analysis
Our next technical focus is improving embedded image handling within documents:
- Image captioning system:
- Implement image recognition algorithms
- Generate descriptive captions for embedded images
- Enable text-based search for visual content
- Connect visual elements with text context
- Technical goals:
- Build a multi-modal extraction pipeline
- Develop a visual element classification
- Create a searchable metadata scheme for images
Large-Scale Document Handling
Addressing technical challenges with very large documents:
- Processing documents with thousands of pages:
- Develop optimized pagination and processing strategies
- Implement efficient sampling techniques
- Design memory-efficient extraction methods
- Maintain consistent performance across file sizes
- Target improvements:
- Linear performance scaling with document size
- Consistent extraction quality regardless of document length
- Optimized resource utilization for large documents
Stay Tuned for More Improvements
Our Layout Extraction engine addresses the challenges of processing structured content in documents. By identifying and solving specific technical limitations, we've improved the system's ability to handle both plain text and tabular information.
This project involved systematic analysis and targeted engineering to overcome document processing constraints. We're continuing to work on additional improvements, particularly in image analysis and large document handling.
These advancements directly enhance our AI product offerings like AI Assistant and Knowledge Bases, enabling them to leverage richer, layout-aware data for more accurate and insightful responses. By improving how we understand and extract document content, we're empowering users with smarter, more reliable AI assistance.
Start your free trial today and experience the difference in intelligent document processing.





